John ODonnell

A home page to expand on my data science projects. All source code can be found on my GitHub profile!
Please Contact for Resume.
Email: johnodonnell123@gmail.com
Phone: (936) 537 0533
View LinkedIn Profile
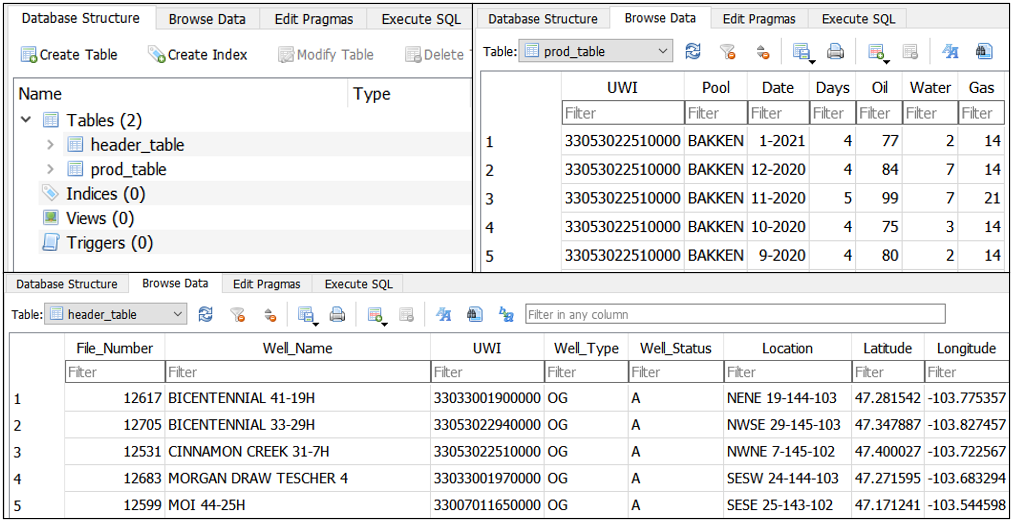
Scraping Production data for Oil and Gas Wells and Storing the data in a SQLite3 Database
Description: In this project I use Scrapy to retrieve and organize data for ~15,000 oil and gas wells. There are two structures of data that need to be scraped, one being the general information for each well, and the second being the production history of the well (time-series format). Two Scrapy Spiders are created as well as two pipelines to push this data into a local, lightweight SQLite 3 database making the data suitable for analysis.
Getting the URLs (start_urls)
The links for each subsequent page are not found within the HTML of previous pages, so new responses cannot be generated the traditional way. URLs will need to be explicitly defined in the start_urls attribute. Inspecting our URL, the tail end has a query string parameter with a file number. The website allows for the export of these file numbers with some other useful metrics. The file numbers were exported and filtered as to only keep those for relevant wells, then imported into Python and the master list is created using a list comprehension.
df = pd.read_csv(r'C:\Users\johno\Python\CSVs\file_numbers.csv')
file_nums = df['FileNo'].astype(str).tolist()
url = 'https://www.dmr.nd.gov/oilgas/feeservices/getwellprod.asp?filenumber='
class HeadersSpider(scrapy.Spider):
name = 'headers'
start_urls = [url + file_num for file_num in file_nums]
Getting Access
The data scraped here comes from a webpage that requires a subscription, and therefore has sign-in credentials. Default request headers are overwritten in the settings.py file and basic credentials are provided with base64 encoding. These are not working credentials shown here, they have been altered.
DEFAULT_REQUEST_HEADERS = {'Authorization': 'Basic am9obm9kb25uZWxsOiNIdW1ibGU0VFg='}
Parse Method (for headers/general data)
Each page looks slightly different, fields are missing/out of order etc. The structure of the HTML is irregular, and requeres some creativity. Queries on the response object need to be very specific, therefore xPath was used. Each node containing some text (field label) is selected, then the following sibling node to get the data needed.
After some unsucessful tests in the Scrapy Shell, it was found that some <tbody> elements were left out by the developer, and were added in by Chrome. Replacing these elements with a forward slash was the remedy.
def parse(self, response):
yield {
'File_Number': response.xpath("(//text()[contains(., 'NDIC File No: ')]//following-sibling::node()/text())[1]").get(),
'Well_Name' : response.xpath("normalize-space((//text()[contains(., 'Current Well Name: ')]//following-sibling::node()/text())[1])").get(),
...
'Perf_Interval' : response.xpath("((//text()[contains(., 'Perf')])[1]//following-sibling::node()/text())[1]").get().replace("=","-"),
'Cum_Oil' : response.xpath("((//text()[contains(.,'Oil')])[1]//following-sibling::node()/text())[1]").get(),
'Cum_Gas' : response.xpath("((//text()[contains(.,'Gas')])[1]//following-sibling::node()/text())[1]").get(),
'Cum_Water' : response.xpath("((//text()[contains(.,'Water')])[1]//following-sibling::node()/text())[1]").get()
}
Parse Method (for production/time-series data)
This was more straightforward as this data is organized in a table and is consistent betweeen pages. A variable is created for the collection of table rows, which is then looped through as data for each row is extracted. Another field is scraped from the page outside of the table to become a common key between these two datasets.
def parse(self, response):
rows = response.xpath("//table[@id='largeTableOutput']//tr")
for row in rows:
yield {
'UWI' : response.xpath("(//text()[contains(., 'API')]//following-sibling::node()/text())[1]").get().replace("-",""),
'Pool' : row.xpath('.//td[1]/text()').get(),
'Date' : row.xpath('.//td[2]/text()').get(),
'Days' : row.xpath('.//td[3]/text()').get(),
'Oil' : row.xpath('.//td[4]/text()').get(),
'Water' : row.xpath('.//td[6]/text()').get(),
'Gas' : row.xpath('.//td[7]/text()').get()
}
Pipelines
Two pipelines are defined allowing for the creation of two separate tables in our database. Below is the Production pipeline, which is nearly identical to the Header pipeline but shorter (fewer fields). A new class is defined with 3 methods.
1) open_spider creates the connection to our database (and creates the database if it does not exist), it creates the table with the specified fields and data types, then commits those changes.
2) close_spider is called at the very end and closes our connection to the database.
import sqlite3
class SQLlitePipeline_Production(object):
def open_spider(self,spider):
self.connection = sqlite3.connect("Well_DataBase.db")
self.c = self.connection.cursor()
try:
self.c.execute('''
CREATE TABLE prod_table(
UWI INT,
Pool TEXT,
Date DATE,
Days INT,
Oil INT,
Water INT,
Gas INT
)
''')
self.connection.commit()
except sqlite3.OperationalError:
pass
def close_spider(self,spider):
self.connection.close()
3) process_item uses our cursor object along with an INSERT statement and populates the table. The .get( ) method is used to avoid key errors. Changes are committed and the item is returned.
def process_item(self, item, spider):
self.c.execute('''
INSERT INTO prod_table (UWI,Pool,Date,Days,Oil,Water,Gas) VALUES(?,?,?,?,?,?,?)
''', (
item.get('UWI'),
item.get('Pool'),
item.get('Date'),
item.get('Days'),
item.get('Oil'),
item.get('Water'),
item.get('Gas')
))
self.connection.commit()
return item
Pipelines are activated by definition in the ITEM_PIPELINES dictionary with their priority numbers.
ITEM_PIPELINES = {
'NDIC.pipelines.SQLlitePipeline_Production': 300,
'NDIC.pipelines.SQLlitePipeline_Headers': 200
}
Result
The SQLite database now has 2 tables, one for header data, the other with production/time-series data. Both tables are related by the UWI key and can be combined with a simple SQL JOIN statement. Originally, this data was essentially useless due to its lack of accessability, now it is in a structured, organized, and accessible database.