John ODonnell

A home page to expand on my data science projects. All source code can be found on my GitHub profile!
Please Contact for Resume.
Email: johnodonnell123@gmail.com
Phone: (936) 537 0533
View LinkedIn Profile
Cluster Analysis for Rock Typing
Description: K-means clustering is used to discover primary rock types in a deep well drilled in the Williston Basin. The project begins by identifying primary rock types for a large section of rock spanning ~9,000’, then focuses on a smaller section of rock (~60’) to identify specific layers in a reservoir. Two unique models are built, however the process is only covered one time as the only difference is the amount of data fed into the model.
Data Context:
Operators drilling for oil and gas want to understand the subsurface reservoirs that they are trying to produce from, and one of the most common ways of doing so is by “logging” a well. A well is drilled vertically to some depth, and a tool is run inside the hole with sensors and measurements are taken. From these measurements, we infer properties about the rock that cannot be measured directly such as porosity, permeability, and oil saturation. Different rock types such as sandstones, limestones, and claystones have distinctly different readings on these tools. Here I hope to provide a very high level overview of some of the common logs.
- Gamma Ray (GR): Measures the natural radioactivity of the rock
- Density (RHOZ): Measures electron density, which is closely tied to bulk density
- Neutron (NPHI): Measures the hydrogen content of the formation which is related to its porosity and/or mineralogy
If you are interested in learning more, here is a useful quick-look chart that shows many more logs and their expected response in different rock types.
Machine Learning: What is K-Means Clustering? Why Bother?
K-Means clustering is an unsupervised learning algorithm that attempts to uncover structures within the dataset it is provided. In one sentence: the algorithm will cross plot all of our variables against each other and see if there are any obvious groups (clusters) in which the points can then be categorized. In the context of this project, we will be looking to see if different rock types are discernable with this methodology. This is something that petrophysicists have been doing for decades manually and has proven incredibly valuable. Why use machine learning instead of doing this manually?
-
Time: This process can be done for thousands of wells, millions of rows of data, in a matter of minutes. This type of project would take weeks if not months of concentrated effort traditionally.
-
Bias: It is repeatable, the subjectivity of the interpreter is minimized. There is still room for interpretation however it is bounded and more easily explained.
-
Exploration: In many cases, the algorithm will find relationships that we didn’t know existed but make sense in a physical space and can be very valuable once we are aware of them. It important to remember we don’t have it all figured out and remain open to new ideas and learning something.
Reading a well log (.las file) into a Pandas DataFrame:
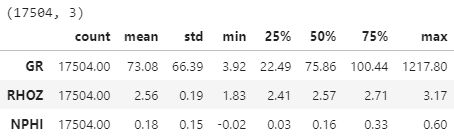
We see that we have a DataFrame indexed by depth, with data every 0.5 feet. We have 21543 rows and 55 logs.
# Import .las file into a LASFile object (from lasio package)
las = lasio.read(r"path_to_file")
# Create DataFrame
df = las.df()
# Observe DataFrame
df.head()

Trimming our DataFrame
We won’t be using 55 logs in our analysis, as most of them are either irrelevant for this study or are highly correlated with another log (providing no unique information and a increasing dimensionality). We can achieve good results with the 3 most fundamental logs that were mentioned earlier (GR, RHOZ, NPHI). The RHOZ log is trimmed to reasonable values, and fortunately this removes all the other suspect data as it occurs over the same interval. We are also dropping the first 2000’ of data as it covers a homogenous unit and is simply not interesting for this project.
# Create a copy to manipulate
df2 = df.copy()
# Filter to the logs we need and reasonable values
df2 = df2[['GR','RHOZ','NPHI']]
df2 = df2[df2['RHOZ'].between(1.8,3.2)]
# Drop first 2000 feet of data
df2 = df2[df2.index > 2000]
# Drop rows missing values
df2.dropna(inplace=True)
# Inspect
print(df2.shape)
df2.describe().transpose()
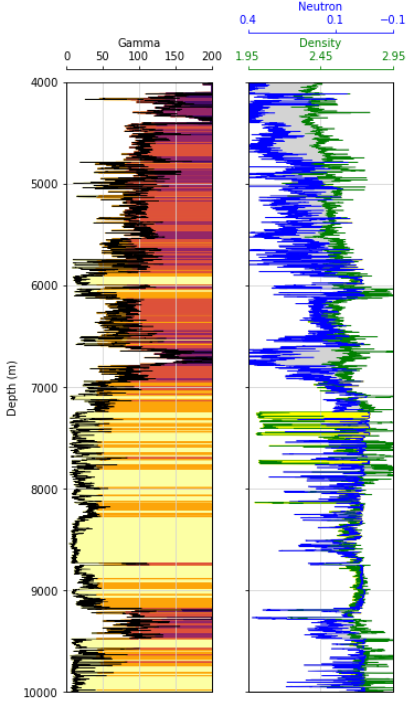
Viewing Logs with Matplotlib
Credit here to Andy McDonald and all of the work he has done with petrophysics in Python. Here in this log plot we have two tracks. The first has our Gamma Ray log that has been shaded to highlight variability. The second track contains the NPHI & RHOZ logs. They have been placed on the same track and their relationship with one another has been shaded (a common petrophysical technique). This plotting function can be found on my GitHub.
Preparing Data for Clustering:
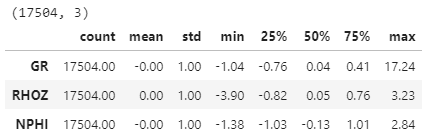
We need to scale our data so that they have similar variances. Our clustering algorithm will want to make these clusters more/less circular in cross plot space, so if the variance among our features are materially different this will lead to the variables with smaller variance getting more weight/being more influential. Our variances here are not terribly different, but it never hurts to standardize and is considered good practice.
Scikit-Learn’s StandardScaler will transform our distributions to have a mean of 0 and a standard deviation of 1.
from sklearn.preprocessing import StandardScaler
# Create the scaler and standardize the data
scaler = StandardScaler()
df2_std = scaler.fit_transform(df2)
# Create DataFrame from standardized data
df2_std = pd.DataFrame(df2_std, columns = df2.columns)
# Inspect
print(df2_std.shape)
df2_std.describe().transpose()
Create the model
We create our model and specify how many clusters we want to create. There are methods to determine how many clusters we should look for, however when working with mixed mediums like rocks the decision is rarely straightforward. I have found it best to take an iterative approach and err on the side of too many clusters. If we have too many clusters we can always combine some together, if too few we may not identify an important rock type. We can also specify other hyperparameters at this time, but the defaults meet our needs in this case.
# Create model
cluster_model = KMeans(n_clusters = 6)
# Fit to our DataFrame
cluster_model.fit(df2_std)
# Get the cluster labels into our standardized and non-standardized DataFrames
df2_std['Clusters'] = cluster_model.labels_
df2['Clusters'] = cluster_model.labels_
View Results
There are two ways to view results. One is with cross plots, and the other on our log plot.
1) 2D and 3D Cross plots
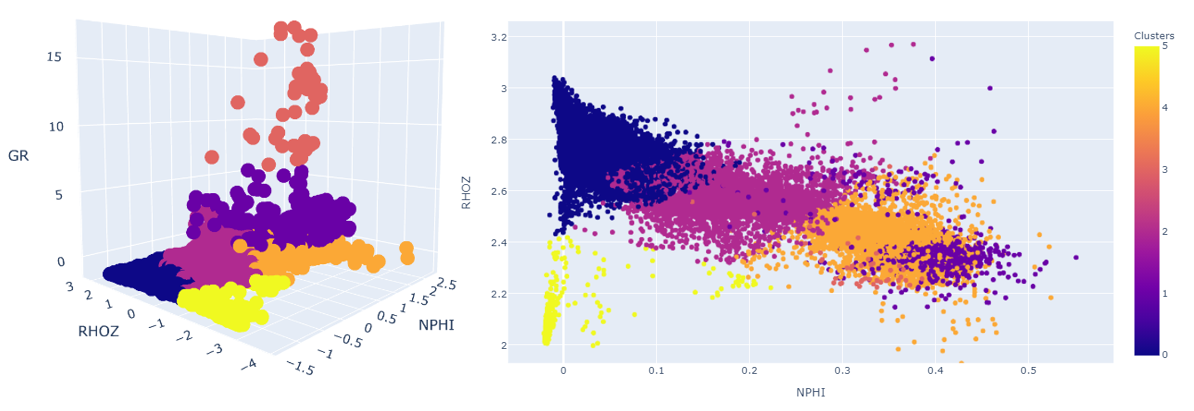
These can be interesting when we have clearly definable groups that separate out nicely, however when we are working with a medium such as a rock formation (highly variable combination of minerals), it might appear we don’t have any discernable groups. Let’s look at the log plot.
2) Log Plot
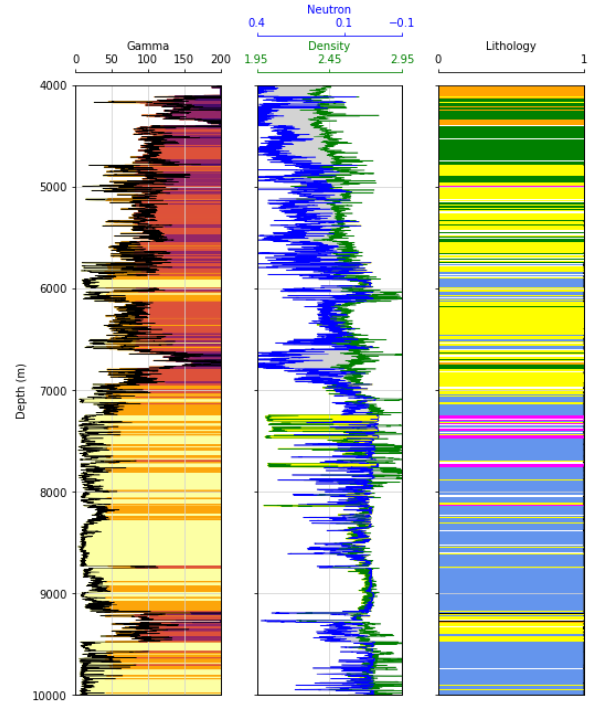
This is a much more intuitive view! We can see visually how some of our log responses are translating into different clusters. Let’s zoom in on a section of the column…
Interpretation:
Zooming in on the pink colored clusters, we can see that they have very low gamma readings, and our density log (green) is reading very low. This is a common response of salt; these are salt beds and they cause a host of issues for operators all around the world. One of which we can see here, note how our green RHOB log appears to read erratically around these beds, this is due to poor borehole conditions caused by these salts.
Salt can also lead to well integrity issues and can cause a well to fail which is not only costly to fix but also halts any production from that well. Identifying these layers and mapping them can help operators plan for special casing designs over these intervals, possibly saving millions in future remediation.
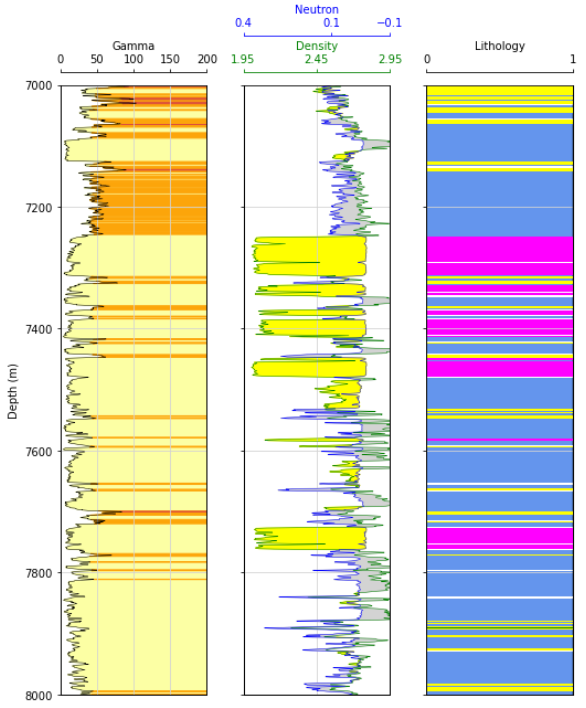
Moving further down section to the primary formation of interest in the basin (Bakken formation), we see some interesting trends. This is the only section of the entire well in which we see this cluster represented by the color black. These are the upper and lower bakken shales, and they are the primary source for the oil in the bakken petroleum system. The blue cluster is interpreted to be carbonate rock, which has little to no porosity and does not hold notable oil. The yellow cluster defines the primary reservoirs for the petroleum system, which are filled with hydrocarbons and have produced hundreds of millions of barrels of oil.
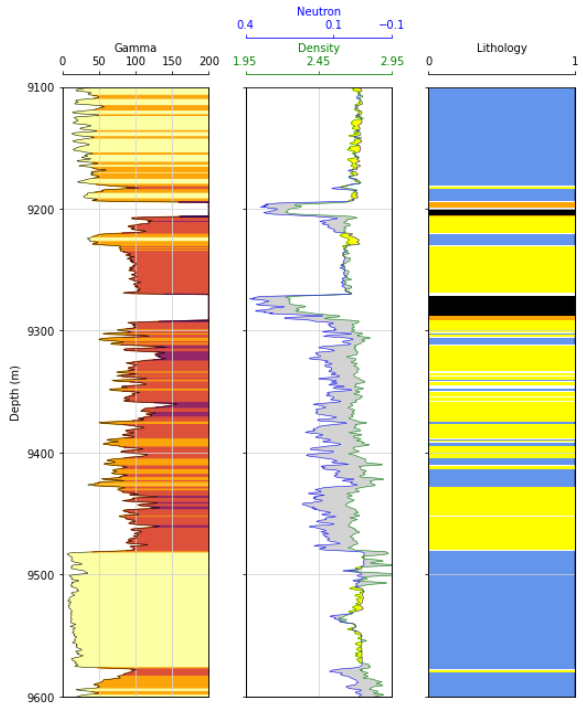
Getting Granular:
It can be valuable to identify the primary rock types for the entire basin using a clustering algorithm on the entire section of rock as detailed above, but sometimes we want to get specific. Another use of this tool is to limit our section of rock to a single interval and generate clusters to parse out this formation into smaller units for classification/ranking. In this example I will zoom in on the Middle Bakken reservoir, which is the most prolific formation in the Williston Basin.

If we were to limit our DataFrame and create a new clustering model on just this small subset of data, we would return what is shown below.
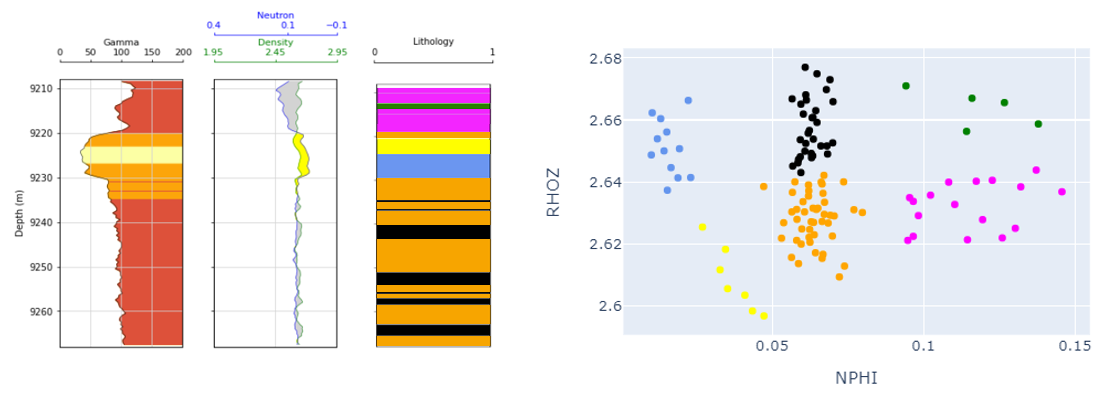
This is a good example of possibly using too many clusters, in which the interpreter could then combine them! I would interpret the pink and green clusters to both represent a dolomitic rock type, while the yellow and blue clusters represent a less favorable carbonate layer. The orange and black clusters might remain separate clusters, as the orange appears to have slightly lower density, which could be a function of the mineralogy or the porosity (either way it is systematically different).
This can be incredibly valuable, because different rock types have different reservoir characteristics and lead to differential oil production. Knowing that in one area of the basin we see a large amount of the favorable pink/green cluster (dolomite), we would expect to see better performance here than in another area that is dominated by the carbonate bed (yellow/blue).
Expansion / Future Work:
This final approach to using this tool that I would like to briefly touch on is building a model using data from the just the Middle Bakken formation, using data from multiple wells.
Why would that be valuable?
- Building a k-means model with data for one well, using 6 clusters, means that 6 groups will be identified in this well (all clusters will be present)
- What if there are unique rock types in different parts of the basin, seen in some wells and not in others? Our previously created model will not uniquely identify them and just know to add a new cluster, they will be shoehorned into one of the existing cluster groups
- Building a model using the data from multiple wells, allows for the identification of all unique groups. We would them use this master model to predict the clusters for each individual well. Some wells may in fact contain all 6 clusters, while others are more homogenous and only have 2-3.
- Mapping the data spatially allows us to see where some rock types thicken, thin, or completely disappear which can be incredibly valuable when comparing two different areas from a business development perspective.